A
Akash Das
June 18, 2025•3 views
Scaling Event Processing: Lessons & Architecture
Published 6/18/2025•4 min read min read
#event-processing#kafka#apache-flink#microservices#scalability#real-time-data
🛠️ Building a Scalable Event Processing System: Lessons from the Trenches
In today’s digital ecosystems, real-time event processing is more than a technical necessity — it’s the backbone of system intelligence. From ad tech to recommendation systems, the ability to collect, process, and act on user and system-generated signals in real time can shape the core business value.
In this post, we share the architectural journey of building a scalable, extensible, and fault-tolerant event processing system, drawing from practical experience in building feedback pipelines for a complex digital platform.
🎯 The Problem Space
When dealing with millions of users and billions of events per day, conventional batch-processing models begin to break down:
- Delayed feedback loops lead to stale decisions.
- System silos make integration costly and brittle.
- Data inconsistencies arise due to asynchronous failures.
We needed a system that would:
- Process events in near real-time.
- Feed multiple downstream systems — from billing to analytics — through a unified interface.
- Be resilient, extensible, and future-proof.
🔧 The Initial Architecture: Minimal and Modular
In our first iteration, simplicity was key. The system was designed around three main components:
- Client Emitters – Users or systems generate events in structured JSON or Protobuf payloads.
- Message Broker (Kafka) – High-throughput ingestion pipeline.
- Event Processors – Stateless consumers that transform and route events to destinations like data lakes, dashboards, or external APIs.
This architecture was battle-tested in production for simple use cases like logging user interactions, validating API latencies, and feeding BI dashboards.
🚨 The Scaling Challenge
As the system matured, challenges emerged:
- Vendor Integrations: Multiple partners required data in different formats.
- Data Bloat: Event payloads grew with new metadata (user context, device info, tags).
- Complex Enrichment: Events needed to be combined with pricing, user profiles, and campaign logic before routing.
- Replay & Ordering Guarantees: Certain workflows needed exactly-once semantics.
We realized we needed more than just a pipeline — we needed a platform.
🧱 Enter the Event Orchestration Layer
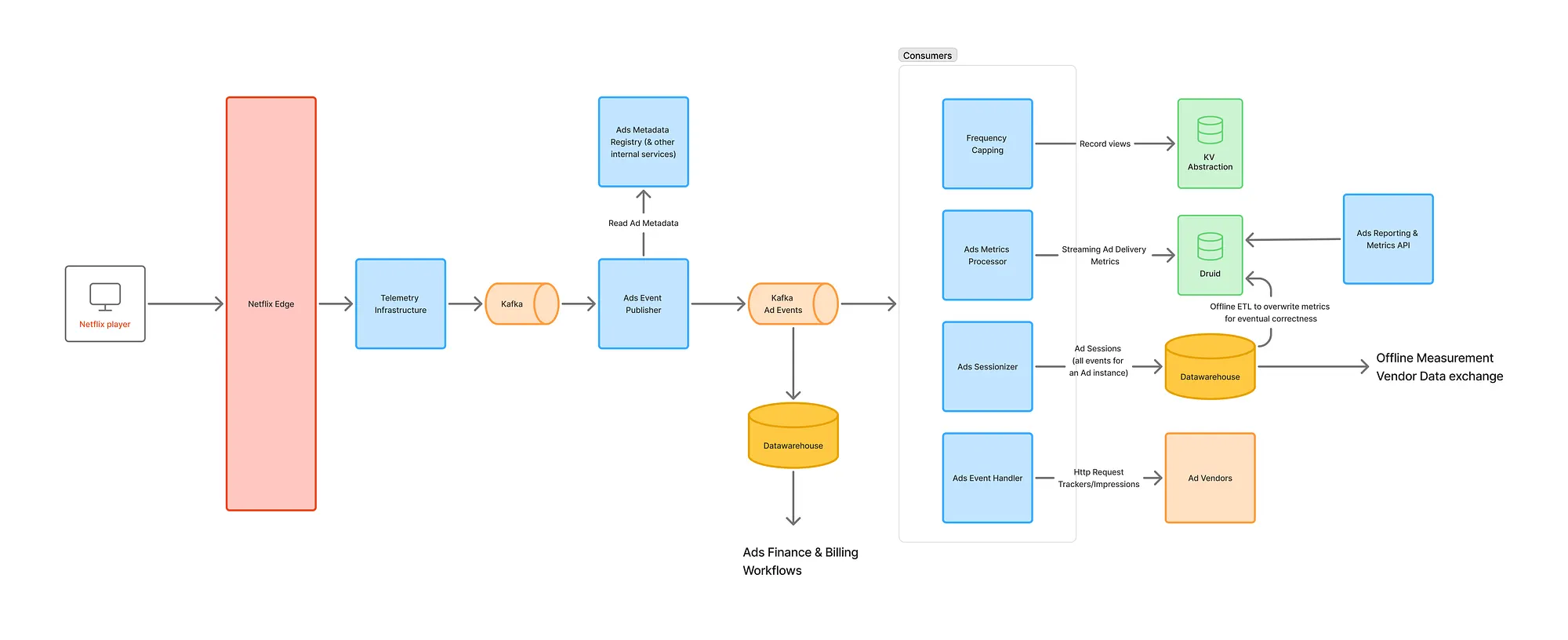
To address scale and extensibility, we introduced a new architectural primitive: the Event Orchestration Layer, built on:
- Key-Value Metadata Registry: Instead of sending large payloads with every event, metadata is cached and referenced via opaque tokens.
- Central Event Enrichment Service: Resolves tokens, joins metadata, computes derived fields, and emits canonical events.
- Stream Abstractions: Apache Flink for sessionization, metrics aggregation, and stateful processing.
- Unified Schema Contracts: Enforced via Protobuf + Avro, versioned and validated upstream.
This resulted in:
✅ Reduced memory and bandwidth footprint on clients ✅ Seamless vendor integrations with pluggable destinations ✅ Simplified data contracts and downstream responsibilities ✅ High resilience through checkpointed state and retries
📊 Real-Time Consumers: Orchestrated for Impact
Here’s how downstream systems interact with the pipeline today:
- Frequency Capping: Aggregates impression counts per user, ad, and context for real-time decisioning.
- Billing & Revenue: Offline workflows cross-reference enriched event logs for invoicing and reconciliation.
- Campaign Metrics: Flink-based metrics engine powers real-time dashboards via Druid.
- Vendor Webhooks: Asynchronous fan-out of tracking events with retries and observability.
Each service is loosely coupled but adheres to the single source of truth emitted by the orchestration layer.
🧪 Observability & Quality
Quality of event data is paramount. To maintain trust in our pipeline:
- Automated contract validation during CI/CD protects downstream systems.
- Synthetic events are replayed hourly to validate sessionization and billing logic.
- Dead-letter queues catch and report anomalies, preserving availability without silent failure.
🛣️ What’s Next
Our roadmap includes:
- Cross-stream deduplication for live and delayed events
- Native support for ad click + QR scan events
- GDPR-compliant opt-out signaling across all channels
- Migration to unified telemetry platform for all media types (video, display, native)
We’re also evaluating WASM-based sandboxing to allow safe third-party transformations inline.
🧠 Key Takeaways
- Platform over pipelines: As use-cases scale, pipelines must evolve into orchestrated platforms with contract-driven design.
- Tokenization + Metadata registry is a scalable pattern to abstract heavy, evolving payloads.
- Separation of concerns across producers, processors, and consumers enables faster iteration and safer deployments.
- Observability is non-negotiable in event-driven systems. Treat telemetry as a product.
🙌 Final Thoughts
Building a reliable, extensible event processing system is both an engineering and product journey. It demands strong abstractions, ruthless prioritization, and deep empathy for downstream consumers.
We're excited about what comes next. Whether you’re building your own pipeline or iterating on legacy systems, we hope these learnings help guide your path.
Feel free to share thoughts, feedback, or questions in the comments below. And yes — we’re hiring.
Comments (3)
A
Akash Das@dasakash.edu·about 1 year ago
hi
A
Akash Das@akashd2664·about 1 year ago
mew
A
Akash Das@akashd2664·10 months ago
mew2